网页抓取:PHP实现网页爬虫方式小结
本文共 880 字,大约阅读时间需要 2 分钟。
来源:
抓取某一个网页中的内容,需要对DOM树进行解析,找到指定节点后,再抓取我们需要的内容,过程有点繁琐。LZ总结了几种常用的、易于实现的网页抓取方式,如果熟悉JQuery选择器,这几种框架会相当简单。
一、Ganon
项目地址: http://code.google.com/p/ganon/
文档: http://code.google.com/p/ganon/w/list
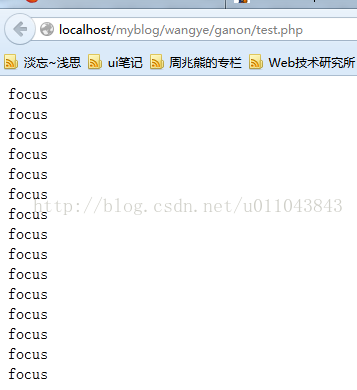
测试:抓取我的网站首页所有class属性值是focus的div元素,并且输出class值
class, "\n"; }?>
结果:
二、phpQuery
项目地址:
文档:
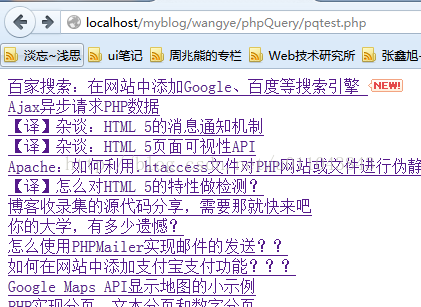
测试:抓取我网站首页的article标签元素,然后出书其下h2标签的html值
find('h2')->html().""; } ?>
结果:
三、Simple-Html-Dom
项目地址: 文档:
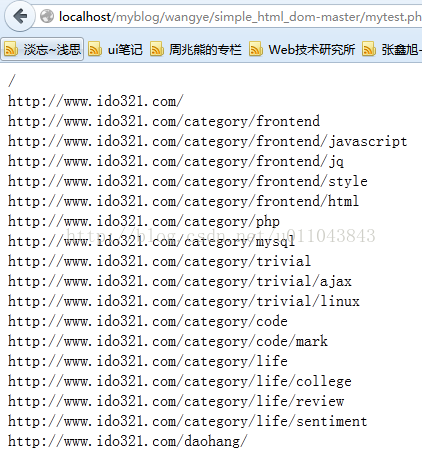
测试:抓取我网站首页的所有链接
find('img') as $element)// echo $element->src . '';//找到所有链接foreach($html->find('a') as $element) echo $element->href . ''; ?>
结果:(截图是一部分)
四、Snoopy
项目地址:
文档:
测试:抓取我的网站首页
fetch($url); //获取所有内容 echo $snoopy->results; //显示结果// echo $snoopy->fetchtext ;//获取文本内容(去掉html代码)// echo $snoopy->fetchlinks($url) ;//获取链接// $snoopy->fetchform ;//获取表单 ?>
结果:

五、手动编写爬虫
如果编写能力ok,可以手写一个网页爬虫,实现网页抓取。网上有千篇一律的介绍此方法的文章,LZ就不赘述了。有兴趣了解的,可以百度 php 网页抓取。
ps:资源分享
常见的开源爬虫项目请戳:
下一篇:
你可能感兴趣的文章
Bootstrap 4重大更新,亮点解读
查看>>
Angular CLI ng常用命令整理
查看>>
git回到指定版本命令
查看>>
cordova-plugin-splashscreen设置启动页面和图标
查看>>
cordova-plugin-media音频播放和录制
查看>>
Visual Studio 2017使用Emmet风格编写Html--ZenCoding
查看>>
C# Newtonsoft.Json JObject移除属性,在序列化时忽略
查看>>
Http缓存机制(转)
查看>>
C# 本地时间格式,UTC时间格式,GMT时间格式处理
查看>>
Windows系统搭建GitServer--Bonobo Git Server
查看>>
Bootstrap3 datetimepicker控件之smalot的使用
查看>>
小程序Canvas隐藏问题处理
查看>>
基于Zookeeper的Curator分布式锁实现
查看>>
来谈谈 Java 反射机制,动态代理是基于什么原理?
查看>>
JVM 内存模型
查看>>
iOS之苹果自带的json解析NSJSONSerialization(序列化)
查看>>
iOS中坐标转换
查看>>
java 基础二
查看>>
java基础(三)方法/数组/堆栈/
查看>>
java基础(四)二维数组/
查看>>